Scrapy
Kurulum
pip install Scrapydiyerek terminalden kurulumu yapabilirsiniz.- Şu anda 1.5 sürümünü kurdum ve python 2.7 ile 3.4+ destekliyor.
Shell Ortamında İşlemler
Terminalden
scrapy shell <hedef_web_sitenin_URL_adresi>diyerek shell ortamında hedef olarak belirttiğiniz sitenin crawl edilmesi sonucu dönen data (response) üzerinde çalışabilirsiniz.- Örnek;
scrapy shell http://quotes.toscrape.com/random. - Bu komutu çalıştırınca aşağıdaki gibi bir sonuç ekranı gelecektir.
- Örnek;
(env) kayace@kayace-K53SV ~/scrapy $ scrapy shell http://quotes.toscrape.com/random2018-06-07 22:40:00 [scrapy.utils.log] INFO: Scrapy 1.5.0 started (bot: scrapybot)2018-06-07 22:40:00 [scrapy.utils.log] INFO: Versions: lxml 4.2.1.0, libxml2 2.9.8, cssselect 1.0.3, parsel 1.4.0, w3lib 1.19.0, Twisted 18.4.0, Python 3.5.2 (default, Nov 23 2017, 16:37:01) - [GCC 5.4.0 20160609], pyOpenSSL 18.0.0 (OpenSSL 1.1.0h 27 Mar 2018), cryptography 2.2.2, Platform Linux-4.4.0-98-generic-x86_64-with-LinuxMint-18.1-serena2018-06-07 22:40:00 [scrapy.crawler] INFO: Overridden settings: {'LOGSTATS_INTERVAL': 0, 'DUPEFILTER_CLASS': 'scrapy.dupefilters.BaseDupeFilter'}2018-06-07 22:40:00 [scrapy.middleware] INFO: Enabled extensions:['scrapy.extensions.memusage.MemoryUsage',...]2018-06-07 22:40:00 [scrapy.middleware] INFO: Enabled downloader middlewares:['scrapy.downloadermiddlewares.httpauth.HttpAuthMiddleware',... 'scrapy.downloadermiddlewares.stats.DownloaderStats']2018-06-07 22:40:00 [scrapy.middleware] INFO: Enabled spider middlewares:['scrapy.spidermiddlewares.httperror.HttpErrorMiddleware', ...]2018-06-07 22:40:00 [scrapy.middleware] INFO: Enabled item pipelines:[]2018-06-07 22:40:00 [scrapy.extensions.telnet] DEBUG: Telnet console listening on 127.0.0.1:60232018-06-07 22:40:00 [scrapy.core.engine] INFO: Spider opened# HEDEF SITEDEN 200 YANI BASARILI CEVABI DONDU/GELDI2018-06-07 22:40:01 [scrapy.core.engine] DEBUG: Crawled (200) <GET http://quotes.toscrape.com/random> (referer: None)[s] Available Scrapy objects:[s] scrapy scrapy module (contains scrapy.Request, scrapy.Selector, etc)[s] crawler <scrapy.crawler.Crawler object at 0x7fc99d67ccf8>[s] item {}[s] request <GET http://quotes.toscrape.com/random>[s] response <200 http://quotes.toscrape.com/random>[s] settings <scrapy.settings.Settings object at 0x7fc99d67cd68>[s] spider <DefaultSpider 'default' at 0x7fc99d28c6d8>[s] Useful shortcuts:[s] fetch(url[, redirect=True]) Fetch URL and update local objects (by default, redirects are followed)[s] fetch(req) Fetch a scrapy.Request and update local objects [s] shelp() Shell help (print this help)[s] view(response) View response in a browser>>> >>> # BURADAN ITIBAREN BIZE DONEN DATA UZERINDE ISLEMLER YAPACAGIZ- Shell ortamında
response.textdediğimiz zaman sayfa içeriğihtml tag'leri de dahil cevap olarak döner. Aşağıdaki data bize dönen cevap:
x\n<html lang="en">\n<head>\n\t <meta charset="UTF-8">\n\t <title>Quotes to Scrape</title>\n <link rel="stylesheet" href="/static/bootstrap.min.css">\n <link rel="stylesheet" href="/static/main.css">\n</head>\n<body>\n <div class="container">\n <div class="row header-box">\n <div class="col-md-8">\n <h1>\n <a href="/" style="text-decoration: none">Quotes to Scrape</a>\n </h1>\n </div>\n <div class="col-md-4">\n <p>\n \n <a href="/login">Login</a>\n \n </p>\n </div>\n </div>\n \n\n <div class="row">\n <div class="col-md-8">\n\n <div class="quote" itemscope itemtype="http://schema.org/CreativeWork">\n <span class="text" itemprop="text">“If you can't explain it to a six year old, you don't understand it yourself.”</span>\n <span>by <small class="author" itemprop="author">Albert Einstein</small>\n <a href="/author/Albert-Einstein">(about)</a>\n </span>\n <div class="tags">\n Tags:\n <meta class="keywords" itemprop="keywords" content="simplicity,understand" /> \n \n <a class="tag" href="/tag/simplicity/page/1/">simplicity</a>\n \n <a class="tag" href="/tag/understand/page/1/">understand</a>\n \n </div>\n </div>\n\n <nav>\n <ul class="pager">\n \n \n </ul>\n </nav>\n </div>\n <div class="col-md-4 tags-box">\n \n </div>\n</div>\n\n </div>\n <footer class="footer">\n <div class="container">\n <p class="text-muted">\n Quotes by: <a href="https://www.goodreads.com/quotes">GoodReads.com</a>\n </p>\n <p class="copyright">\n Made with <span class=\ 'sh-red\'>❤</span> by <a href="https://scrapinghub.com">Scrapinghub</a>\n </p>\n </div>\n </footer>\n</body>\n</html>- CSS seçicileri kullanarak sayfadaki
<small class='author' ..>etiketinde bulunan dataya erişmek için:
xxxxxxxxxx>>> response.css('small.author').extract()['<small class="author" itemprop="author">Albert Einstein</small>']- Gördüğünüz üzere bir liste (yani dizi, array) döndü.
xxxxxxxxxx>>> response.css('small.author').extract()[0]'<small class="author" itemprop="author">Albert Einstein</small>'>>> response.css('small.author').extract_first()'<small class="author" itemprop="author">Albert Einstein</small>' - Burada [index] veya
extract_first()diyerek string değere erişebiliriz.
xxxxxxxxxx>>> response.css('small.author::text').extract_first()'Albert Einstein'ETIKET.SINIF_ADI::textdiyerek etikete ait text'e erişebiliyoruz.- Yazara ait alıntı söz
<span class='text' ... >etiketinde duruyor. Erişmek için:
xxxxxxxxxx>>> response.css('span.text::text').extract_first()"“If you can't explain it to a six year old, you don't understand it yourself.”"- Sayfaya ait
aetiketindekitagclass'ında bulunan etiketleri almak için:
xxxxxxxxxx>>> response.css('a.tag::text').extract()['simplicity', 'understand']XPath ile data üzerinde çalışmak
- Hedef siteden verileri CSS seçicileri kullanarak aldığımız gibi
xpathkullanarak da alabiliriz.
xxxxxxxxxx>>> response.xpath('//small[@class="author"]/text()').extract()['Albert Einstein']- Burada
text()'i method(fonksiyon) gibi kullanıyoruz.
xxxxxxxxxx>>> response.xpath('//div[@class="tags"]/a[@class="tag"]/@href').extract()['/tag/simplicity/page/1/', '/tag/understand/page/1/']>>> response.xpath('//div[@class="tags"]/a[@class="tag"]/text()').extract()['simplicity', 'understand']>>> - yazdığımız
xpathiledivaltındaaHTML etiketinintagclass'ınınhrefattribute'unu alabiliyoruz. Yani URL adresiniaHTML etiketinden alabiliyoruz.
- yazdığımız
- yazdığımız örnekte ise 1. örnekteki gibi yazıp sadece
text()'leri aldık.
- yazdığımız örnekte ise 1. örnekteki gibi yazıp sadece
Scrapy Proje Oluşturma
$ scrapy startproject benim_projem diyerek proje oluşturabilirsiniz.
xxxxxxxxxx├── adnan_scrapy│ ├── adnan_scrapy│ │ ├── __init__.py│ │ ├── items.py│ │ ├── middlewares.py│ │ ├── pipelines.py│ │ ├── __pycache__│ │ ├── settings.py│ │ └── spiders # HEDEF SITELER ICIN SPIDER KLASORU│ │ ├── __init__.py│ │ └── __pycache__│ └── scrapy.cfgadnan_scrapyadında proje oluşturduktan sonra.spidersklasörü altındascrapy genspider OrumcekAdam HEDEF_SITEkomutunu vererek, OrumcekAdam isminde spider oluşturduk. Hedef site olarak datoscrape.comsitesini gösterdik.
xxxxxxxxxx(env) kayace@kayace-K53SV ~/scrapy/adnan_scrapy/adnan_scrapy/spiders $ scrapy genspider OrumcekAdam toscrape.comCreated spider 'OrumcekAdam' using template 'basic' in module: adnan_scrapy.spiders.OrumcekAdam(env) kayace@kayace-K53SV ~/scrapy/adnan_scrapy/adnan_scrapy/spiders $ tree ..├── __init__.py├── OrumcekAdam.py└── __pycache__ └── __init__.cpython-35.pycspiders/OrumcekAdam.py: Aşağıdaki gibi bir spider python dosyası oluştu.
xxxxxxxxxx# -*- coding: utf-8 -*-import scrapyclass OrumcekadamSpider(scrapy.Spider): name = 'OrumcekAdam' # Spider adı allowed_domains = ['toscrape.com'] # Spider'ın gezeceği domainlerin listesi. start_urls = ['http://toscrape.com/'] # Bilgi çekeceğimiz URL'ler. def parse(self, response): pass- Şimdi bu dosyayı düzenleyelim:
xxxxxxxxxx# -*- coding: utf-8 -*-import scrapyclass OrumcekadamSpider(scrapy.Spider): name = 'OrumcekAdam' allowed_domains = ['toscrape.com'] ######################################### ## 'random' sub_domainini yerleştirdik ## start_urls = ['http://quotes.toscrape.com/random'] def parse(self, response): yield{ 'author_name' : response.css('small.author::text').extract_first(), 'text' : response.css('span.text::text').extract_first(), 'tags' : response.css('a.tag::text').extract_first(), }- Şimdi
scrapy runspider OrumcekAdam.pydiyerek spider'ı çalıştırınca, terminalden şöyle bir çıktı alıyoruz:
xxxxxxxxxx.......2018-06-07 23:49:38 [scrapy.core.engine] DEBUG: Crawled (200) <GET http://quotes.toscrape.com/random> (referer: None)2018-06-07 23:49:38 [scrapy.core.scraper] DEBUG: Scraped from <200 http://quotes.toscrape.com/random>{'author_name': 'Albert Einstein', 'tags': 'life', 'text': '“Life is like riding a bicycle. To keep your balance, you must keep moving.”'}..........'finish_time': datetime.datetime(2018, 6, 7, 20, 49, 38, 949815), 'item_scraped_count': 1, 'log_count/DEBUG': 4, 'log_count/INFO': 7, 'memusage/max': 52740096,- Site random quote yayınladığı için bu defa farklı bir quote döndü. Ancak istediğimiz verileri siteden çektik.
- Dönen datayı
jsondosyasına yazmak için scrapy runspider OrumcekAdam.py -o DOSYA_ADI.json- Dosya içeriği:
xxxxxxxxxx[{"author_name": "Albert Einstein", "tags": "life", "text": "\u201cLife is like riding a bicycle. To keep your balance, you must keep moving.\u201d"}]- Hedef siteyi değiştirerek çoklu veri çekmeyi görelim.
xxxxxxxxxx# -*- coding: utf-8 -*-import scrapyclass OrumcekadamSpider(scrapy.Spider): name = 'OrumcekAdam' allowed_domains = ['toscrape.com'] # 'random' sub_domainini yerleştirdik # start_urls = ['http://quotes.toscrape.com/random'] start_urls = ['http://quotes.toscrape.com'] def parse(self, response): for quote in response.css('div.quote'): m_dict = { 'author_name' : quote.css('small.author::text').extract_first(), 'text' : quote.css('span.text::text').extract_first(), 'tags' : quote.css('a.tag::text').extract(), # tag'ler çok olabilir. } yield m_dictstart_urlsadresinde random subdomaini kaldırdık. Web sayfasını ziyaret ederseniz 10 ade quote sergilendiğini göreceksiniz.- Hedef sitede her quote bir
divaltında bulunduğu içinfordöngüsü ile bütün quote'lar üzerinde gezebiliriz. - Çıktı olarak json dosyasına yazdığımızda aşağıdaki gibi bir sonuç alırız.
xxxxxxxxxx[{"author_name": "Albert Einstein", "text": "\u201cThe world as we have created it is a process of our thinking. It cannot be changed without changing our thinking.\u201d", "tags": ["change", "deep-thoughts", "thinking", "world"]},{"author_name": "J.K. Rowling", "text": "\u201cIt is our choices, Harry, that show what we truly are, far more than our abilities.\u201d", "tags": ["abilities", "choices"]},{"author_name": "Albert Einstein", "text": "\u201cThere are only two ways to live your life. One is as though nothing is a miracle. The other is as though everything is a miracle.\u201d", "tags": ["inspirational", "life", "live", "miracle", "miracles"]},{"author_name": "Jane Austen", "text": "\u201cThe person, be it gentleman or lady, who has not pleasure in a good novel, must be intolerably stupid.\u201d", "tags": ["aliteracy", "books", "classic", "humor"]},{"author_name": "Marilyn Monroe", "text": "\u201cImperfection is beauty, madness is genius and it's better to be absolutely ridiculous than absolutely boring.\u201d", "tags": ["be-yourself", "inspirational"]},{"author_name": "Albert Einstein", "text": "\u201cTry not to become a man of success. Rather become a man of value.\u201d", "tags": ["adulthood", "success", "value"]},{"author_name": "Andr\u00e9 Gide", "text": "\u201cIt is better to be hated for what you are than to be loved for what you are not.\u201d", "tags": ["life", "love"]},{"author_name": "Thomas A. Edison", "text": "\u201cI have not failed. I've just found 10,000 ways that won't work.\u201d", "tags": ["edison", "failure", "inspirational", "paraphrased"]},{"author_name": "Eleanor Roosevelt", "text": "\u201cA woman is like a tea bag; you never know how strong it is until it's in hot water.\u201d", "tags": ["misattributed-eleanor-roosevelt"]},{"author_name": "Steve Martin", "text": "\u201cA day without sunshine is like, you know, night.\u201d", "tags": ["humor", "obvious", "simile"]}]Pagination with Scrapy
- Web sayfalarında
next, 2, 3 ..gibi sayfalanmış web içeriğini çekmeyi öğrenelim.
xxxxxxxxxx<nav> <ul class="pager"> <li class="next"> <a href="/page/2/">Next <span aria-hidden="true">→</span></a> </li> </ul></nav>- Üstteki kod
http://quotes.toscrape.com/sayfasının source code'unun bir parçası.
xxxxxxxxxx# -*- coding: utf-8 -*-import scrapyclass OrumcekadamSpider(scrapy.Spider): name = 'OrumcekAdam' allowed_domains = ['toscrape.com'] # 'random' sub_domainini yerleştirdik # start_urls = ['http://quotes.toscrape.com/random'] start_urls = ['http://quotes.toscrape.com'] def parse(self, response): for quote in response.css('div.quote'): m_dict = { 'author_name': quote.css('small.author::text').extract_first(), 'text': quote.css('span.text::text').extract_first(), 'tags': quote.css('a.tag::text').extract(), } yield m_dict next_page_url = response.css('li.next > a::attr(href)').extract_first() if next_page_url: next_page_url = response.urljoin(next_page_url) yield scrapy.Request(url=next_page_url, callback=self.parse) # yeniden istek yap ve parse methodunu callback(yeniden çağır)next_page_urlile sonraki sayfanın URL'ini aldık.response.urljoinile root URL ile birleştirdik.scrapy.Requestile deparsemethodunu tekrar çağırıp hedef siteye tekrar istek yaptık.- Bu spider'ı çalıştırınca kaç adet sayfa var ise içerisinde gezinip verileri çekecektir.
scrapy runspider OrumcekAdam.py -o pagination.jsondiyerek json dosyasında aldığınız veriyi görebilirsiniz. - Terminalden bakınca alınan data adedini:
'item_scraped_count': 100,ekran çıktısı üzerinde görebilirsiniz.
Page Detail
- Web sayfalarında bir yazarın, ürünün vb. detay sayfası olur ve o kimse veya ürün hakkında açıklamalar yazar.
- Bu bölümde yazarın detay sayfasından adını ve doğum tarihini alacak kodları görelim.
xxxxxxxxxx# -*- coding: utf-8 -*-import scrapyclass OrumcekadamSpider(scrapy.Spider): name = 'orumcekadam' allowed_domains = ['toscrape.com'] start_urls = ['http://quotes.toscrape.com'] def parse(self, response): """ div altında quote class'ında span tag'inde <a> tag'inde href attribute'u bu bize yazarın yanında bulunan about linkini veriyor. link : /author/Yazar-Adı """ urls = response.css('div.quote > span > a::attr(href)').extract() # author URL'leri for url in urls: url = response.urljoin(url) # /author/Yazar-Adi URL'sini ekle # her yazarın adını ve doğum tarihini almak için parse_details methodunu çağırıyoruz yield scrapy.Request(url=url, callback=self.parse_details) # pagination link next_page_url = response.css('li.next > a::attr(href)').extract_first() if next_page_url: next_page_url = response.urljoin(next_page_url) yield scrapy.Request(url=next_page_url, callback=self.parse) def parse_details(self, response): # burada yonlendirildigimiz sayfadan istedigimiz bilgileri aliyoruz. # biz ismini ve dogum tarihini alacağız yield { # h3 taginde "author-title" class'ının texti bize yazar adını verir 'name': response.css('h3.author-title::text').extract_first(), # span taginde author-born-date class'ının texti bize doğum tarihi bilgisini veriyor 'birth_date': response.css('span.author-born-date::text').extract_first(), }- Terminalde shell ortamında bir kaç örnek üzerinden bakarsak üstteki kodları anlayabiliriz.
xxxxxxxxxx$ scrapy shell http://quotes.toscrape.com/>>> import pprint>>> >>> pprint.pprint(response.css('div.quote > span > a::attr(href)').extract())['/author/Albert-Einstein', '/author/J-K-Rowling', '/author/Albert-Einstein', '/author/Jane-Austen', '/author/Marilyn-Monroe', '/author/Albert-Einstein', '/author/Andre-Gide', '/author/Thomas-A-Edison', '/author/Eleanor-Roosevelt', '/author/Steve-Martin']>>> response.url'http://quotes.toscrape.com/'>>> URLS = response.css('div.quote > span > a::attr(href)').extract()>>> response.urljoin(URLS[0])'http://quotes.toscrape.com/author/Albert-Einstein'>>> response.urljoin(URLS[1])'http://quotes.toscrape.com/author/J-K-Rowling'>>> pprintile güzel ekran çıktıları görebiliriz.authorURL'leri aldıktan sonraurljoinile absolute URL'i elde ediyoruz.for url in urlsiçerisindeyield scrapy.Request(url=url, callback=self.parse_details)diyerek detay sayfasına request yapıyoruz. Toplamda 50 tane yazar verisini almış olacağız.
Infinite Scrolling
- Twitter'daki gibi web browser'ı scroll yapınca(aşağı kaydırdıkça) verilerin yüklenmesi yani infinite scrolling ile verileri nasıl alabileceğimizi göreceğiz.
http://quotes.toscrape.com/scrollsayfasında infinite scrolling bulunuyor. Tarayıcı üzerinden mouse sağ tıklayıp "inspect/öğe incele" dedikten sonranetworktab'ına geçip scrolling yani aşağı kaydırma yapıncaquotes?page=SAYFA_NOgöreceksiniz. Üzerinde tıkladığınızda scroll yaparken network bilgilerini göreceksiniz.- Request URL olarak:
http://quotes.toscrape.com/api/quotes?page=SAYFA_NOgöreceksiniz. - Şimdi terminal üzerinden bu URL ile çalışalım.
xxxxxxxxxx$ scrapy shell http://quotes.toscrape.com/api/quotes?page=4>>>>>> import json # dönen data üzerinde kolay işlem yapmak için json dataya dönüştüreceğiz.>>> data = json.loads(response.text)>>> data['quotes'][0]>>> data['quotes'][0]['author']['name']- Yukarıdaki shell ortamında 4.sayfadaki veriler üzerinde çalışabilirsiniz.
- Python koduna bakalım.
xxxxxxxxxx# -*- coding: utf-8 -*-import json # eklemeyi unutmaimport scrapyclass OrumcekadamSpider(scrapy.Spider): name = 'infinite' api_url = 'http://quotes.toscrape.com/api/quotes?page={}' # sayfa artacagi için URL taslak olacak page dinamik olacak start_urls = [api_url.format(1)] # format(arg) methodu süslü parantez yerine arg degiskenini ekler. page sürekli artacak. def parse(self, response): # bütün veriyi data degiskeninde tutuyoruz ve dikkat ederseniz json verisi olarak aldık data = json.loads(response.text) # json formatındaki veriyi Python dictionary'e veya list'e dönüştürür. for quote in data['quotes']: # bütün qoutes'ları data['quotes'] da görebilirsiniz yield { 'author_name': quote['author']['name'], 'text': quote['text'], 'tags': quote['tags'], } if data['has_next']: next_page = data['page'] + 1 # sayfa numarasi 2,3,4 ... bitene kadar birer birer artsin yield scrapy.Request(url=self.api_url.format(next_page), callback=self.parse)self.api_url.format(next_page)sonraki url için sayfa numarasını veriyoruz.
Form Submitting
quotes.toscrape.comsitesindeLoginlinkine tıkladığımızda bizihttp://quotes.oscrape.com/loginsayfasına götürecek ve aşağıdaki kaynak kodun olduğu forma götürecek.- Login olmak için herhangi bir değer girebilirsiniz textbox'lara.
xxxxxxxxxx<form action="/login" method="post" accept-charset="utf-8" > <input type="hidden" name="csrf_token" value="ehPwBXpgDLCMUQHEbFvjIVfZouNkRlArTdtznGYxqWiOScsmaKJy"/> <div class="row"> <div class="form-group col-xs-3"> <label for="username">Username</label> <input type="text" class="form-control" id="username" name="username" /> </div> </div> <div class="row"> <div class="form-group col-xs-3"> <label for="username">Password</label> <input type="password" class="form-control" id="password" name="password" /> </div> </div> <input type="submit" value="Login" class="btn btn-primary" /> </form>- Login olduktan sonra aşağıdaki gibi
Goodreads pagelinkini göreceksiniz.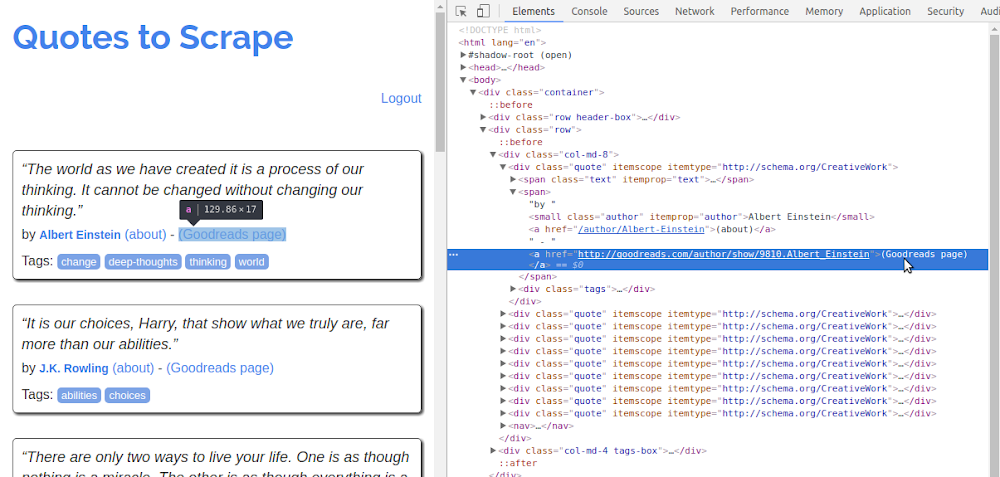
- Python koduna göz atalım:
xxxxxxxxxx# -*- coding: utf-8 -*-import jsonimport scrapyclass OrumcekadamSpider(scrapy.Spider): name = 'infinite' login_url='http://quotes.toscrape.com/login' start_urls = [login_url] def parse(self, response): # extract the csrf token value #csrf token value log-in olacak her kullanıcı için güvenlik kodu token = response.css('input[name="csrf_token"]::attr(value)').extract_first() # log-in olmak için csrf_token, username, password'u gönderiyoruz form'a data={ 'csrf_token' : token, # sag tikla view source deyip form tag'lerinde name="csrf_token" olani al 'username' : 'abc' , 'password' : 'abc', } # Post isteği gönder, yani log-in olmak icin yield scrapy.FormRequest(url=self.login_url, formdata=data, callback=self.parse_quotes) def parse_quotes(self,response): """ log-in olduktan sonra ana sayfayı parse edecek """ for q in response.css('div.quote'): yield{ 'author_name' : q.css('small.author::text').extract_first(), 'author_url' : q.css( ## small.author'dan sonra gelen her <a> tagini seçer ve href = "goodreads.com" ile eşleşen linkleri al 'small.author ~ a[href *= "goodreads.com"]::attr(href)' # css selector kullanildi ).extract_first() }- Login olduktan sonra her yazarın
goodreadslinklerini aldık.
xxxxxxxxxx[{"author_url": "http://goodreads.com/author/show/9810.Albert_Einstein", "author_name": "Albert Einstein"},{"author_url": "http://goodreads.com/author/show/1077326.J_K_Rowling", "author_name": "J.K. Rowling"},{"author_url": "http://goodreads.com/author/show/9810.Albert_Einstein", "author_name": "Albert Einstein"},{"author_url": "http://goodreads.com/author/show/1265.Jane_Austen", "author_name": "Jane Austen"},{"author_url": "http://goodreads.com/author/show/82952.Marilyn_Monroe", "author_name": "Marilyn Monroe"},{"author_url": "http://goodreads.com/author/show/9810.Albert_Einstein", "author_name": "Albert Einstein"},{"author_url": "http://goodreads.com/author/show/7617.Andr_Gide", "author_name": "Andr\u00e9 Gide"},{"author_url": "http://goodreads.com/author/show/3091287.Thomas_A_Edison", "author_name": "Thomas A. Edison"},{"author_url": "http://goodreads.com/author/show/44566.Eleanor_Roosevelt", "author_name": "Eleanor Roosevelt"},{"author_url": "http://goodreads.com/author/show/7103.Steve_Martin", "author_name": "Steve Martin"}]
Yorumlar